Population stellaire de l'amas M13¶
Réalisation d'un diagramme couleur / luminosité...¶
En n'utilisant que des bibliothèques du langage Python.
Les lignes qui suivent exposent pas par pas, en n'excluant pas les tâtonnements et les erreurs.
Bibliothèques à installer¶
En plus des bibliothèques usuelles : numpy, astropy, matplotlib, il faut installer astroquery.
Dans le contexte du MOOC FUN sur la recherche reproductible¶
Celui-ci définit un environnement spécifique appelé mooc-rr-jupyter pour les personnes qui veulent utiliser les notebook Jupyter (qui est l'outil utilisé pour réaliser cette note).
Pour installer les bibliothèques qui peuvent manquer, il faut, dans l'ordre :
- Activer l'environnement
conda activate mooc-rr-jupyter - Installer astropy et scipy s'ils ne le sont pas. Par exemple :
conda install -n mooc-rr-jupyter -c astropy - Installer astroquery :
conda install -n mooc-rr-jupyter -c conda-forge/label/cf202003 astroquery
Suite à des erreurs dans l'exécution du code, j'ai utilisé la commande conda update -n base -c defaults conda qui semble "réaccorder" les paquets (sans exclure certains messages d'alarme.
Test : astroquery est-il reconnu ?¶
from astroquery.simbad import Simbad
result_table = Simbad.query_object("m13")
result_table.pprint(show_unit=True)
Un message d'alarme qui n'empêche pas l'obtention d'un résultat.
Passons à l'étape suivante, et initialisons les bibliothèques.
import numpy as np
import matplotlib.pyplot as plt
from astropy.modeling import models, fitting
from astroquery.vizier import Vizier
import scipy.optimize
Chargement d'un catalogue des étoiles de M13.
Celui qui a été trouvé (par des méthodes non expliquée ici), porte le numéro : J/A+AS/102/397G
# Vizier.ROW_LIMIT.set('999999999')
catalog = Vizier.get_catalogs('J/A+AS/102/397G')
Important : pour le moment on n'effectue aucun choix sur les champs importés, ni sur le nombre de lignes chargées en mémoire.
Par défaut, c'est 50 lignes. Mais comment paramétrer cette valeur ?
print(catalog)
Pour le moment on est limité à 50 lignes. Comment accéder à tout ? Quels sont les noms de colonnes ?
print(catalog[0][0])
Il est possible maintenant d'extraire les deux colonnes qui importent et de tracer un premier graphique.
Premiers graphiques¶
a = catalog[0]['Bmag']
b = catalog[0]['B-V']
plt.scatter(a,b)

Paramétrer le nombre de lignes chargées¶
La table de données, correspond avec l'argument [0] qui suit le nom du catalogue.
On fait ici l'hypothèse que la paire de chrochets qui suit permet de définir "à la Python" les lignes chargées. Par exemple : première table et lignes de 0 à 10 se paramétrera : [0][0:10].
Faisons le test :
table = Vizier.get_catalogs('J/A+AS/102/397G')[0][0:10]
print(table)
Si l'on veut charger les lignes 2 à 5, on peut supposer ceci (qui pourra être vérifié avec le listage précédent) :
table2 = Vizier.get_catalogs('J/A+AS/102/397G')[0][2:6]
print(table2)
Et cela fonctionne comme attendu.
Diagramme pour les mille premières lignes¶
Partant sur les hypothèses suivantes, on va essayer de charger les 1000 premières lignes, et de tracer le diagramme.
table3 = Vizier.get_catalogs('J/A+AS/102/397G')[0][0:1000]
print(table3)
a = table3['Bmag']
b = table3['B-V']
plt.scatter(a,b)
En fait, c'est raté. Le paramétrage de forme [0][0:10]ne fonctionne que pour le chargement par défaut, c'est à dire les 50 premières lignes.
Il faut trouver autre chose.
Dans les échanges sur un forum, trouvé ce paramètre : Vizier.ROW_LIMIT = -1
Vizier.ROW_LIMIT = -1
table4 = Vizier.get_catalogs('J/A+AS/102/397G')[0][0:1000]
print(table4)
a = table4['Bmag']
b = table4['B-V']
plt.scatter(a,b)

Paramétrer la taille des points dans le diagramme¶
Vizier.ROW_LIMIT = -1
table4 = Vizier.get_catalogs('J/A+AS/102/397G')[0][0:1000]
a = table4['Bmag']
b = table4['B-V']
plt.scatter(a,b,s=1) # s=1 : un point de 1 pixel de diamètre

Vizier.ROW_LIMIT = -1
table4 = Vizier.get_catalogs('J/A+AS/102/397G')[0][0:1000]
a = table4['Bmag']
b = table4['B-V']
plt.scatter(b,a,s=1) # s=1 : un point de 1 pixel de diamètre

L'échelle des magnitude est dans l'ordre inverse.
Voici maintenant un diagramme HR, selon la disposition conventionnelle, réalisé avec 3000 étoiles.
Vizier.ROW_LIMIT = -1
table4 = Vizier.get_catalogs('J/A+AS/102/397G')[0][0:3000]
a = table4['Bmag']
b = table4['B-V']
fig = plt.figure(1, figsize=(5,6)) # dimensions du cadre
plt.plot(b, a, linestyle='none', marker = 'o', c = 'red', markersize = 2)
axes = plt.gca()
axes.set_xlim(-0.25,1.60) # échelle des températures
axes.set_xlabel("Couleur : B-V")
axes.set_ylim(13, 21) # échelle des magnitudes
axes.set_ylabel("Magnitudes")
# affiche les points dans l'ordre du diagramme HR
axes.invert_yaxis()
# axes.invert_xaxis()

Comparaison avec un diagramme "standard"¶
L'image qui sert de fond est tiré de l'article de Wikipedia.
Explications¶
Le diagramme HR utilise une échelle des magnitudes graduée en magnitudes absolues. Celle-ci n'étant pas disponible dans le catalogue d'étoiles de M13, on ne pourra caler "en hauteur" les deux diagrammes.
Par contre, M13 étant très loin, on peut considérer que les étoiles sont toutes à la même distance de nous, ce qui permet d'avoir une perception cohérente des rapports de magnitudes (des étoiles entre elles).
L'indice de couleur (B-V) est cohérente sur les deux graphiques.
L'image ci-jointe est un montage où un cadre blanc situe le diagramme des étoiles de M13 sur le diagramme standard.
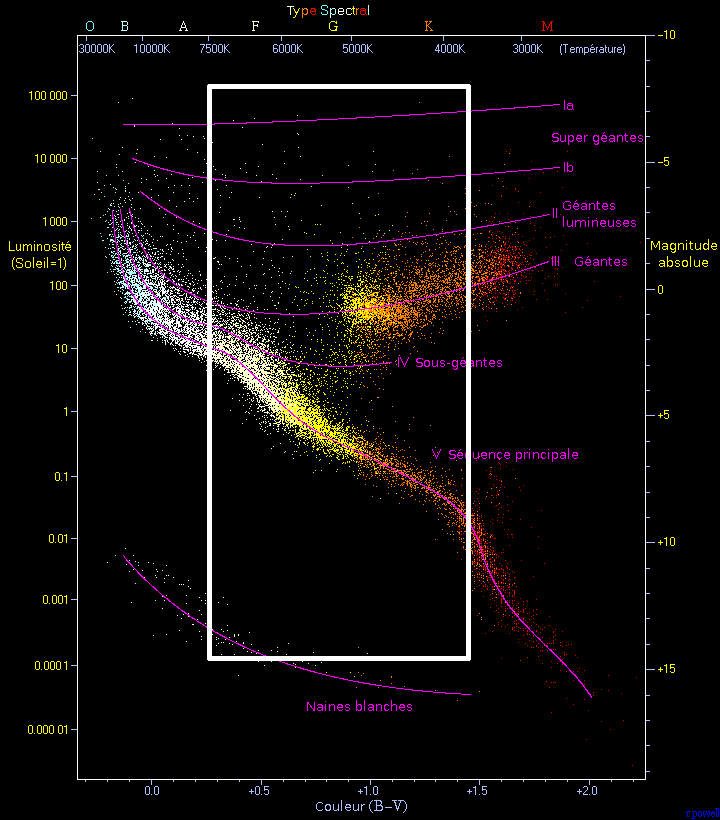 .
.
Bilan.¶
- Ouverture et chargement du catalogue.
- Paramétrage du nombre de lignes chargées.
- Pas de paramétrage des colonnes chargées.
- Diagramme avec une taille de point défini.
- Étiquettes le long des axes et orientation des graduations.
Envies¶
À défaut de termes plus savants...
Maintenant que l'on a compris que l'on réalisait un diagramme HR de l'amas M13, il est tentant de voir ce que donneront les diagrammes d'autres amas globulaires de la Galaxie.
Sont-ils tous nés à une même époque ? Le nuage de matière initial était-il de même composition pour tous ?
Si on ne sait pas répondre, la densité relative d'un amas, ou le nombre d'étoiles ont-ils une incidence sur le diagramme ?
Si deux diagrammes sont légèrement différents "au pif", existe-t-il des "outils" qui permettent de trancher "par les quantités" (les nombres) : moyennes, courbes, pente de celle-ci. Et que sais-je encore ? Si ces outils existent, vais-je y comprendre quelque chose ?
Et, plus important, comment aider d'autres à y comprendre aussi quelque chose ?
Pour finir par une phrase rassurante : le travail ne manquera pas.