LE DIAGRAMME HR (2)
Table of Contents
Tentative pour générer un diagramme HR plus complet en utilisant un catalogue contenant plus d'étoiles.
CHOIX D'UN NOUVEAU CATALOGUE
L'article précédent a montré les limites d'un catalogue souffrant de deux faiblesses :
- Trop peu d'étoiles.
- Ttypes spectraux limités à G, K, M.
Afin d'enrichir le diagramme, il faut trouver un catalogue qui remplisse deux contraintes :
- Contenir des étoiles dans les catégories O B A F G K M.
- Fournir les magnitudes absolues pour un maximum d'étoiles.
Partant de la base de données Vizier, à l'adresse https://vizier.u-strasbg.fr/viz-bin/VizieR il est possible d'accéder au catalogue référencé par V137 D, qui contient, en particulier la magnitude absolue des étoiles.
Extended Hipparcos Compilation (XHIP) (Anderson+, 2012)
De ce catalogue, on extrait à minima : la parallaxe, la magnitude absolue et le type spectral. À cela s'ajouteront les coordonnées équatoriales (qui semblent ajoutées systématiquement).
Le résultat obtenu, par extraction depuis la base entière est enregistré dans un fichier texte, dont on ne garde que les lignes de données (nom : V137D.txt).
Examen du fichier texte (sous Linux)
Descendant du sytème UNIX, Linux est riche en outils en ligne de commande qui sont à la fois rapides, efficaces, et économes en ressources.
- Combien de lignes (et donc d'étoiles dans le fichier texte) ?
wc -l V137D.txt
Réponse : 117955 lignes.
Explication : wc pour word count = compter les mots d'un fichier. Quand on ajoute le paramètre -l le logiciel affiche le nombre de lignes et rappelle le nom du fichier.
- Je voudrais voir le contenu de quelques lignes sans charger le gros fichier dans un logiciel comme Word ou Writer. Comment faire ?
cat V137D.txt | less
00 00 00.2161719 +01 05 20.433864 1 F3 V 00 00 01.0225739 -19 29 55.802316 2 47.79 K3 V 5.87 00 00 01.2051118 +38 51 33.399963 3 429.40 B8V -1.55 00 00 02.0711543 -51 53 36.761095 4 132.53 F0 V 2.45 00 00 02.3927878 -40 35 28.335395 5 G8 III 00 00 04.4856958 +03 56 47.230845 6 K7V 00 00 05.2824295 +20 02 10.011438 7 57.56 K0V 5.84 00 00 06.5585788 +25 53 11.221060 8 M7e Zr0.5 00 00 08.4768713 +36 35 09.451546 9 G5 00 00 08.7397242 -50 52 01.107630 10 91.40 F6 V 3.79 00 00 08.9609833 +46 56 23.987498 11 233.46 A2 0.50 00 00 09.8162051 -35 57 36.798208 12 K4 III 00 00 10.0076601 -22 35 40.937757 13 K0 III 00 00 11.6216289 -00 21 37.650339 14 201.17 K0 0.73 00 00 12.0871407 +50 47 28.266141 15 K2 ... 00 00 20.9316249 -43 21 42.554227 28 191.51 F3/5 V 2.42
Explication : la commande cat liste le fichier à l'écran, le | less arrête le listage quand la page écran est remplie. Lettre q pour quitter, barre d'espace pour continuer.
Remarquer que
- Certaines lignes ne contiennent pas de magnitude absolue (information la plus à droite).
- Quand la parallaxe est donnée (quatrième colonne de donnée (la première est 47.79)), on a également la magnitude absolue (5.87).
- Cela semble cohérent parce que, pour calculer celle-ci, on a besoin de la distance de l'étoile au Soleil… qui se détermine avec la parallaxe.
Conséquences
- Il va falloir éliminer les lignes qui contiennent des informations incomplètes.
- Il serait bien d'enregistrer ce que l'on élimine pour pouvoir revenir dessus et essayer de l'exploiter (au moins d'y réfléchir).
Exemple de code
- Chargement du fichier texte dans une liste.
#!/usr/bin/python3
# -*- coding: utf-8 -*-
import json
import random
data = open("V137D.txt", "r")
source = data.readlines()
data.close() # fermeture du fichier texte
- Création de deux listes qui vont contenir…
- l'une, les données retenues : utiles[]
- l'autre: les lignes incomplètes : incompletes[]
Ces deux listes sont ensuite sauvegardées dans des fichiers .JSON.
Code utilisé :
utiles =[]
incompletes = []
for ligne in source:
if (len(ligne) >=80) and (len(ligne[49:51].strip(" ")) > 0) \
and (len(ligne[74:80].strip(" ")) > 0) and not "s" in ligne :
prov = []
prov.append(ligne[74:80]) # mag absolue
prov.append(ligne[49:51]) # type spectral
utiles.append(prov)
else:
incompletes.append(ligne)
# ~ -- Sauvegarde des données
with open('V137_D.json',"w") as f:
f.write(json.dumps(utiles))
with open('incompletes.json',"w") as f:
f.write(json.dumps(incompletes))
# ~ -- Affichage du nombre de lignes retenues et écartées
print("Nombre de lignes retenues : ", len(utiles))
print("Nombre de lignes incomplètes : ", len(incompletes))
Décompte des résultats :
Nombre de lignes retenues : 59964 Nombre de lignes incomplètes : 57991
Le rapide listage effectué au 1.1.1 le laissait suspecter : la moitié des lignes ne contient pas d'informations exploitables pour le diagramme HR.
UTILISATION D'UN DICTIONNAIRE
… au sens du langage Python.
- Un dictionnaire permet de retrouver quasi instantanément une information associée à une clé.
- Ici il va être utilisé pour associer un type spectral avec une température + une valeur qui sera expliquée plus tard.
Exemple :
{"O0": [40000, 1500], "O1": [38500, 1500], "O2": [37000, 1500], "O3": [35500, 1500], "O4": [34000, 1500], "O5": [32500, 1500],[...], ["M7": [2450, 150]}
Explications :
- Le type spectral O0 est associé à 40000° kelvin et cette valeur pourra varier, en plus ou en moins de 0 à 1500°, par tirage aléatoire.
- Le type spectral M0 est associé à 2450° kelvin et cette valeur pourra varier, en plus ou en moins de 0 à 150°, par tirage aléatoire.
Exemple de code pour la création du dictionnaire :
lettres =["O","B", "A", "F", "G", "K", "M"]
tous_spectres = [[25000, 40000],[10000, 25000], [7500, 10000] , [6000, 7500] , \
[5000, 6000] , [3500, 5000], [2000, 3500]]
dico = {}
i = 0
# ~ Il faut mémosiser le pas dans le dictionnaire en plus de la température
for lettre in lettres:
ligne = tous_spectres[i]
dix_pas = ligne[1] - ligne[0]
un_pas = int(dix_pas/10)
for j in range(10):
temp = ligne[1] + (j * un_pas * -1)
dico[lettre+str(j)] = [temp, un_pas]
i+=1
with open('temperatures2.json',"w") as f:
f.write(json.dumps(dico))
Exemple de code pour l'utilisation
L'intention est d'associer deux fichiers préalablement créés :
- Le fichier des lignes utiles.
- Le fichier de dictionnaire.
Pour générer un fichier qui permettra de générer le diagramme : prepa.json Les éléments rejetés pendant cette opération sont enregistrés dans le fichier rejetes.json
Code :
with open('V137_D.json','r') as g:
utiles = json.load(g)
with open('temperatures2.json','r') as h:
dico = json.load(h)
prepa = []
rejetes = []
for ligne in utiles:
spectre = ligne[1].strip(' ')
# on récupère la liste associée au dictionnaire
if spectre in dico :
intermed = dico.get(spectre)
un = intermed[0] # température "stable"
semence = intermed[1] # valeur pour tirage aléatoire
double = semence * 2
plus = random.randint(1, double)
plus = plus - semence
element = []
# ~ element = [ligne[0], dico.get(spectre)]
element = [ligne[0], un + plus]
# lister les spectres qui ne sont pas dans dico
else:
rejetes.append(ligne) # ils sont enregistrés pour étude
prepa.append(element)
with open('prepa.json',"w") as f:
f.write(json.dumps(prepa))
with open('rejetes.json', 'w') as g:
g.write(json.dumps(rejetes))
print("nb rejetés : ", len(rejetes))
593 étoiles sont rejetées.
LE DIAGRAMME
Le code, limité au minimum, permet de générer l'image attendue.
import matplotlib.pyplot as plt
with open('prepa.json','r') as h:
prepa = json.load(h)
x = []
y = []
for ligne in prepa:
if len(ligne[0].strip(' ')) > 0:
x.append(ligne[1])
y.append(float(ligne[0]))
fig = plt.figure(1, figsize=(6,8)) # dimensions du cadre
plt.plot(x, y, linestyle='none', marker = 'o', c = 'red', markersize = 1)
axes = plt.gca()
axes.set_xlim(2000,35000) # échelle des températures
axes.set_xlabel("Température")
axes.set_ylim(-15, 20) # échelle des magnitudes
axes.set_ylabel("Magnitude absolue")
# affiche les points dans l'ordre du diagramme HR
axes.invert_yaxis()
axes.invert_xaxis()
plt.show()
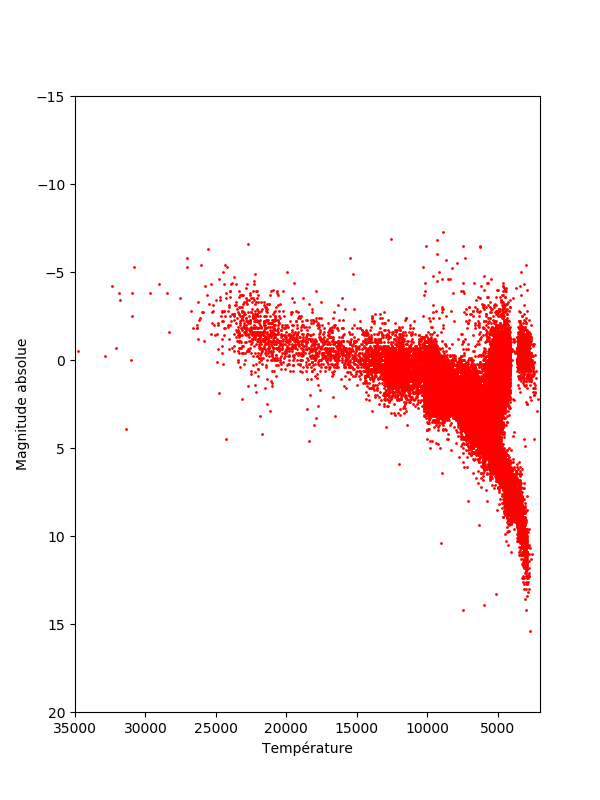
Suite possible
- Le diagramme obtenu ne ressemble pas à celui de Wikipedia. Pourquoi ?
- Exploiter les informations qui, dans le type spectral, définissent la taille de l'étoile : naine, géante… exemple : G8 III et, dans ce cas changer la couleur du point.
- Certains types spectraux "différents" ont été laissé de côté. Peut-on en tirer quelque chose ?
Tambouille (images dans code HTML)
https://orgmode.org/worg/org-tutorials/images-and-xhtml-export.html