LE DIAGRAMME HR
Table of Contents
Tentative pour générer un diagramme HR plus complet en utilisant un catalogue contenant un millier d'étoiles
RÉSUMÉ
Comment établir un diagramme de Herzprung-Russel à partir d'un catalogue d'étoiles disponible sur internet ?
- Choix du catalogue et des zones qui contiennent l'information utile.
- Extraction en utilisant le système de "query" (interrogation) de la base de données Vizier du Centre de Données Spatiales.
- Transformation des données avec le langage Python.
- Réalisation d'une représentation graphique en utilisant la bibliothèque Matplotlib.
Définition
Wikipedia donne la définition suivante :
En astronomie, le diagramme de Hertzsprung-Russell, en abrégé diagramme H-R, est un graphique dans lequel est indiquée la luminosité d'un ensemble d'étoiles en fonction de leur température effective. Ce type de diagramme a permis d'étudier les populations d'étoiles et d'établir la théorie de l'évolution stellaire.
Un diagramme de Hertzsprung-Russell est toujours présenté de la manière suivante :
- la luminosité est en ordonnée, le plus brillant étant en haut ;
- la température effective, ou l'indice de couleur, est en abscisse, le plus chaud étant à gauche.
https://fr.wikipedia.org/wiki/Diagramme_de_Hertzsprung-Russell
Informations nécessaires
La magnitude absolue de chaque étoile
Pour un objet situé en dehors du système solaire, elle est définie par la magnitude apparente qu'aurait l'astre s'il était placé à une distance de référence : 10 parsecs (environ 32,6 années-lumière).
La température de surface
ou tout élément associant celle-ci à la couleur de l'étoile (à préciser).
Si on ne pervient pas à trouver la température de chaque étoile, on utilisera l'échelle des types spectraux.
CATALOGUES
Où trouver des catalogues ?
La base de données atronomiques Vizier, à l'observatoire de Strasbourg propose un grand nombre de catalogues, téléchargeables gratuitement.
Plutôt que de télécharger tout un catalogue, il est possible d'effectuer une extraction par un mode d'interrogation interactif simplifé utilisant des cases à cocher.
On peut utiliser aussi un langage d'interrogation de base de données ressemblant à SQL (une aide à l'apprentissage est proposée).
Ci-dessous, les résultats de trois tentatives pour trouver un catalogue fournissant les informations attendues.
Exemple avec le catalogue Hipparchos.
Partant de cette page : https://vizier.u-strasbg.fr/viz-bin/VizieR il est possible :
- De n'extraire que certains champs en les cochant (partie centrale de l'écran).
- Définir le nombre d'enregistrements à charger (cadre bleu à gauche intitulé Préférences).
- Choisir le format de sortie. (choix ici : "; Separated-Value")
- Valider en cliquant sur le bouton Submit.
Les données sont alors enregistrées au format texte dans le répertoire défini par votre navigateur (ici : Téléchargements).
Examen des données obtenues
Le fichier texte comprend deux parties :
- Une partie en-tête permettant d'interpréter les données qui suivent.
Extrait de l'en-tête
#Column _RAJ2000 (F14.10) Right ascension... #Column _DEJ2000 (F14.10) Declination... #Column HIP (I6) Hipparcos identifier [ucd=meta.id;meta.main] #Column Plx (F7.2) Parallax [ucd=pos.parallax] #Column Hpmag (F7.4) Hipparcos magnitude [ucd=phot.mag;em.opt.V] #Column B-V (F6.3) Colour index [ucd=phot.color;em.opt.B;em.opt.V] #Column e_B-V (F6.3) Formal error on colour index [ucd=stat.error;phot.color;em.opt.B] #Column V-I (F6.3) V-I colour index... _RAJ2000;_DEJ2000;HIP;Plx;Hpmag;B-V;e_B-V;V-I deg;deg; ;mas;mag;mag;mag;mag
- Les données sous forme d'un suite de lignes (une par étoile), formant une table (un ensemble de lignes toutes structurées toutes de la même façon).
Quelques lignes de la table
000.0099710689;-40.5912048615; 5; 3.88; 8.7077; 0.902; 0.013; 0.900 000.0186903971;+03.9464530120; 6; 18.17;12.4488; 1.336; 0.020; 1.550 000.0220110544;+20.0361123159; 7; 17.28; 9.6795; 0.740; 0.020; 0.790
Exemple avec le catalogue "Parrallaxes and Proper Motions…."
Le nom complet étant : Parallaxes and Proper Motions near SGP (Murray+ 1986)
La logique d'interrogation est la même.
Examen des données obtenues
- Un en-tête. Retenons seulement les explications pour les dernières colonnes.
#Column recno (I8) Record number assigned by the VizieR team.
#Column Bmag (F5.2) B magnitude (photographic)
#Column Vmag (F5.2) V magnitude (photographic)
#Column B-V (F5.2) B-V colour index (photographic)
#Column plx (F7.4) Trigonometric parallax (")
_RAJ2000;_DEJ2000;recno;Bmag;Vmag;B-V;plx
deg;deg; ;mag;mag;mag;arcsec
- Une table :
011.43738274;-29.80377328; 1;16.45;15.70; 0.75;-0.0050 011.43778886;-29.71474058; 2;17.01;16.61; 0.40; 0.0070 011.45212148;-29.41635418; 3;13.56;12.90; 0.67; 0.0005
Une meilleure démarche
Partant de la page d'accueil Vizier du CDS (centre de données spatiales) de Strasbourg, à l'adresse :
https://vizier.u-strasbg.fr/viz-bin/VizieR il faut procéder ainsi :
- S'assurer que la zone Search Criteria en haut à gauche est vide.
- Choisir Search for catalogs by column description
- Dans la zone colorée, au centre, cocher Magnitude et color et absolute.
- Valider alors par Find Catalogs en bas à droite.
Une liste de catalogues s'affiche alors dans laquelle on a choisi V/70A : Nearby Stars…
- Cocher la case à gauche du nom du catalogue.
- Choisir Show table details et sélectionner les champs utiles et le format d'exportation.
Exemple des données obtenues :
001.3608;-37.3873;DM-37 15492 ; ;225; 8.63;10.4; M4V ; 001.6896; -7.5220;G 158-27 ; ;214; 13.74;15.4; M7V ; 003.8607;-16.1223;G 158-50 ; ;117; 11.53;11.9; M5V ; 004.5908;+44.0164;DM+43 44 ;A;290; 8.10;10.4; M1V ; 004.6157;+44.0330; ;B;290; 11.06;13.4; M6V ;
Les trois dernières colonnes désignent la magnitude visuelle, la magnitude absolue, la classification spectrale.
Autres catalogues candidats
Le catalogue retenu : étoiles proches du Soleil… ne contient qu'un faible nombre de lignes (moins de mille) et n'incluera peut-être pas tous les types d'étoiles. Y aura-t-il de géantes, des super géantes ?
Quelles seront les conséquences pour le diagramme ?
Deux autres catalogues seront peut-être plus adaptés :
V/32A : étoiles à moins de 25 parsecs du Soleil. V/137D : Extension au catalogue Hipparcos.
Mais en attendant, la démarche va être testée avec le catalogue retenu.
PRÉPARATION DES DONNÉES
Premières décisions
Les données utiles seront placées dans une liste de listes (au sens de Python).
On ne conservera que la magnitude, la magnitude absolue, la classe spectrale.
L'en-tête sera supprimé (dans un éditeur de texte afin de ne garder que le tableau de données).
Les données utilses seront enregistrées dans un fichier au format json.
Contraintes liées au données
Dans chaque ligne, certaines informations peuvent être remplacées par des espaces, ce qui interdit l'usage de la fonction split() de Python.
À la place, il faut extraire les données à partir de leurs positions.
Qui seront, pour ce catalogue :
- magnitude : [38:44] ;
- magnitude absolue : [45:50]
- type spectral : [51:58].
Récupération dans un format facile à exploiter
Dans le code suivant, on récupère les données des 3 premières lignes de la table pour les transférer dans une liste de listes appelée utiles.
On les enregistre ensuite dans un fichier au format json, et le résultat, ainsi récupéré, est listé.
#!/usr/bin/python3 # -*- coding: utf-8 -*- import json data = open("donnees.tsv", "r") source = data.readlines() data.close() utiles =[] print("Depuis le fichier de données") for i in range(3): prov = [] prov.append(source[i][38:44]) prov.append(source[i][45:50]) prov.append(source[i][51:58] ) utiles.append(prov) print(utiles) # Création du fichier json with open('utiles.json',"w") as f: f.write(json.dumps(utiles)) # Lecture et listage with open('utiles.json','r') as g: recup = json.load(g) print("Depuis le fichier json") print(recup)
Depuis le fichier de données [[' 8.63', '10.4 ', ' M4V '], [' 13.74', '15.4 ', ' M7V '], [' 11.53', '11.9 ', ' M5V ']] Depuis le fichier json [[' 8.63', '10.4 ', ' M4V '], [' 13.74', '15.4 ', ' M7V '], [' 11.53', '11.9 ', ' M5V ']]
Exploiter la classification spectrale
Exemple avec la classe B
Étoile bleue-blanche, dont la température de surface est comprise entre 10 000 et 25 000 degrés Kelvin.
Pour donner une information plus précise, on a créé dix subdivisions allant de B0 à B9. B0 est le plus chaud et B9 le moins chaud.
Comment calculer la température pour B0 ? B5 ? B9 ?
Algorithme :
- Calculer la différence entre le minimum et le maximum soit 15 000
- Sachant qu'elle est partagée en dix "pas", valeur d'un pas : 15000∕10
- Retirer cette valeur de zéro à 9 fois de maximum.
Exemple de code Python possible :
tspect = ["B", 10000, 25000] dix_pas = tspect[2] - tspect[1] un_pas = int(dix_pas/10) for i in range(10): temp = tspect[2] + (i * un_pas * -1) print(tspect[0]+str(i), temp)
B0 25000 B1 23500 B2 22000 B3 20500 B4 19000 B5 17500 B6 16000 B7 14500 B8 13000 B9 11500
Exemple pour les classes O, B, A, F, G, K, M
- Pour O, prendre une valeur arbitraire 26000 degrés Kelvin.
- Pour les autres établir une liste de listes selon la logique de l'exemple précédent.
- Générer des entrées dans un dictionnaire permettant d'associer rapidement un type avec une température.
import json lettres =["B", "A", "F", "G", "K", "M"] tous_spectres = [[10000, 25000], [7500, 10000] , [6000, 7500] , \ [5000, 6000] , [3500, 5000], [2000, 3500]] dico = {} i = 0 for lettre in lettres: ligne = tous_spectres[i] dix_pas = ligne[1] - ligne[0] un_pas = int(dix_pas/10) for j in range(10): temp = ligne[1] + (j * un_pas * -1) # print(lettre+str(j), temp) dico[lettre+str(j)] = temp i+=1 dico["O"] = 26000 print("Impression du dictionnaire ") print(dico) # Sauvegarde dans un fichier json. with open('temperatures.json',"w") as f: f.write(json.dumps(dico))
Impression du dictionnaire
{'B0': 25000, 'B1': 23500, 'B2': 22000, 'B3': 20500, 'B4': 19000, 'B5': 17500, 'B6': 16000, 'B7': 14500, 'B8': 13000, 'B9': 11500, 'A0': 10000, 'A1': 9750, 'A2': 9500, 'A3': 9250, 'A4': 9000, 'A5': 8750, 'A6': 8500, 'A7': 8250, 'A8': 8000, 'A9': 7750, 'F0': 7500, 'F1': 7350, 'F2': 7200, 'F3': 7050, 'F4': 6900, 'F5': 6750, 'F6': 6600, 'F7': 6450, 'F8': 6300, 'F9': 6150, 'G0': 6000, 'G1': 5900, 'G2': 5800, 'G3': 5700, 'G4': 5600, 'G5': 5500, 'G6': 5400, 'G7': 5300, 'G8': 5200, 'G9': 5100, 'K0': 5000, 'K1': 4850, 'K2': 4700, 'K3': 4550, 'K4': 4400, 'K5': 4250, 'K6': 4100, 'K7': 3950, 'K8': 3800, 'K9': 3650, 'M0': 3500, 'M1': 3350, 'M2': 3200, 'M3': 3050, 'M4': 2900, 'M5': 2750, 'M6': 2600, 'M7': 2450, 'M8': 2300, 'M9': 2150, 'O': 26000}
Création du fichier préparatoire
Ce fichier rassemble les données permettant de tracer le diagramme.
Il comporte deux champs :
- la magnitude absolue,
- la température.
C'est un fichier json dans lequel sont enregistrés les éléments d'une liste appelée prepa. prepa = [[mag0, temp0],[ mag1, temp1],…]
Création de la liste prepa et enregistrement
Elle va être générée en associant le fichier utiles.json et le fichier temperatures.json.
… ensuite enregistrée dans le fichier prepa.json.
Exemple de code effectuant ces opérations.
import json with open('utiles.json','r') as g: utiles = json.load(g) with open('temperatures.json','r') as h: dico = json.load(h) prepa = [] for ligne in utiles: spectre = ligne[2].strip() if not len(spectre)== 0: element = [] #print(ligne) #print(ligne[1], dico.get(spectre[0:2])) element = [ligne[1], dico.get(spectre[0:2])] prepa.append(element) print("contenu de la liste prepa ") print(prepa) # sauvegarde with open('prepa.json',"w") as f: f.write(json.dumps(prepa))
contenu de la liste prepa [['10.4 ', 2900], ['15.4 ', 2450], ['11.9 ', 2750]]
CRÉATION DU DIAGRAMME
Rappelons ce qui a été écrit au début de l'article :
Un diagramme de Hertzsprung-Russell est toujours présenté de la manière suivante :
- la luminosité est en ordonnée, le plus brillant étant en haut ;
- la température effective, ou l'indice de couleur, est en abscisse, le plus chaud étant à gauche.
Quel outil utiliser pour réaliser le diagramme ?
La bibliothèque libre Mathplotlib est accessible via le langage Python.
Elle permet la réalisation de représentations graphiques 2D.
Liens utilisés
Exemple de code qui fonctionne
import matplotlib.pyplot as plt import json with open('prepa.json','r') as h: prepa = json.load(h) x = [] y = [] for ligne in prepa: if len(ligne[0].strip(' ')) > 0: x.append(ligne[1]) y.append(float(ligne[0])) fig = plt.figure(1, figsize=(5,8)) # dimensions du cadre plt.plot(x, y, linestyle='none', marker = 'o', c = 'red', markersize = 2) axes = plt.gca() axes.set_xlim(2000,26000) # échelle des températures axes.set_xlabel("Température") axes.set_ylim(-15, 20) # échelle des magnitudes axes.set_ylabel("Magnitude absolue") # affiche les points dans l'ordre du diagramme HR axes.invert_yaxis() axes.invert_xaxis() plt.show()
Le diagramme suivant s'affiche :
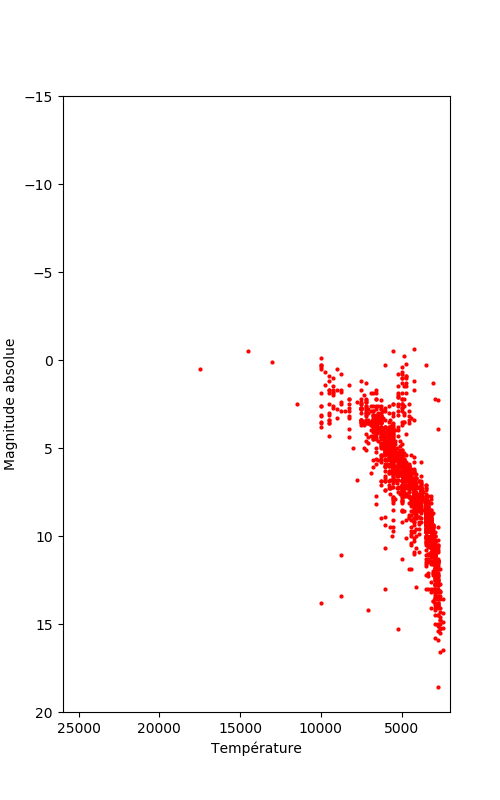
BILAN
Négatif
- Le diagramme HR n'est pas complet. La cause la plus évidente est le faible nombre d'étoiles, proches du Soleil, ce qui limite l'échantillonnage. Les géantes et super géantes sont absentes.
- Les liens sur images ne fonctionnent pas et il faut modifier le code HTML à la main.
Positif
- On a le début d'un diagramme avec deux séries ébauchées : la série principale et les naines blanches.
- Le minimum vital sur Matplotlib est connu.
Et ensuite ?
- Refaire le même travail avec un catalogue plus complet.
- Essayer de faire une représentation 3D des positions des étoiles (de ce catalogue) autour du Soleil.
COMPLÉMENTS
Ressources en ligne
Plusieurs adhérents de l'AAI (Association Astronomique de l'Indre) ont participé, en particulier en proposant des ressources en ligne qui permettaient d'approfondir des points délicats.
Merci donc à Michel Brialix et à Jean-Louis Betoule.
Diagramme de Herzprung-Russel
Type spectral
Mathplotlib
Traitements informatiques
Ou : essais et erreurs
Problème des zones vides
Dans la table de données, certaine lignes ont des "trous" (des espaces, là où l'on s'attend à trouver de l'information.
C'est la raison d'être du code :
spectre = ligne[2].strip(' ') # élimine les espaces
if not len(spectre) == 0: # teste si le champ est non vide
Problème que l'on retrouve quand on teste que la chaine de caractère qui contient la magnitude absolue n'est pas vide, avant de la convertir en float.
C'est la raison du code :
if len(ligne[0].strip(' ')) > 0:
Utilisation de la fonction strip(' ')
Elle permet d'éliminer les espaces inutiles d'une chaîne.
Ajouter des élément à une liste, à un dictionnaire
- liste.append(nouveau)
- À l'intérieur d'une boucle : dico[lettre+str(j)] = temp